第 6 章:编译 dex 字节码为机器码
本文最后更新于:10 个月前
Android 平台的虚拟机的演化:
- Dalvik 虚拟机:采用 JIT
Just-In-Time,即时编译方案,将热点 Java 方法的字节码转换成机器码。 - Android 7.0 以前的 ART 虚拟机:采用 AOT
Ahead-Of-Time,预编译方案,在安装应用程序时就会尝试将 APK 中大部分 Java 方法的字节码转换成机器码。- 劣:应用程序安装时间过长;编译生成的 oat 文件过大。
- Android 7.0 及以后的 ART 虚拟机:综合使用了 JIT 和 AOT 编译方案。
三段式编译器的架构:
| 输入 | 主要工作 | 输出 | |
|---|---|---|---|
| 前端 | 源码 | 解析源码,对其进行词法分析、语法分析、语义分析、生成 IR | IR Intermadiate Representation,中间表示(中间代码、中间语言) |
| 优化器 | 未优化的 IR | 优化 IR比如循环优化、常量传播和折叠、无用代码消除、方法内联优化;合理分配物理寄存器对于因物理寄存器不足导致的无法存储的值,需要生成存/取内存的指令 | 优化后的 IR |
| 代码生成器 | 优化后的 IR | 将 IR 翻译成机器码 | 目标机器的机器码 |
- 三段式的架构具有较强的可拓展性,体现了术业有专攻
编译器开发难度大,开发者很难同时精通这 3 个模块,拆分后,开发者能集中精力于擅长的部分的重要性和必要性:
词法分析和 lex:
- 词法分析的目标是识别输入字符流中的特定单词,其用到的基础技术就是正则表达式。
- lex 可以将 lex 规则文件转换成对应的 C 代码文件,编译这个 C 代码文件就可得到一个可执行程序
可以对输入的字符串按照 lex 规则文件中的规则进行词法分析。 - lex 使用流程:
- 编写 lex 规则文件
比如文件名 simple.lex。 - 使用 lex 工具,执行
lex simple.lex,生成 C 代码文件默认文件名 lex.yy.c。 - 使用编译工具
比如 g++,执行g++ lex.yy.c -o simple -ll,生成可执行程序simple。 - 对 C 代码
比如 test.c进行词法分析,执行simple test.c。
- 编写 lex 规则文件
语法分析需要使用词法分析的结果和 yacc:
- 语法分析的目标是判断语句是否符合语言所规定的语法要求。
- 语法规则是通过文法
最常用的是 BNF 范式来描述的,语法分析的大体过程就是不断对输入语句按照文法进行分析。
- 语法规则是通过文法
- 语法分析有两种分析方法:
- 推导法:自顶向下。
- 适合手工编码实现。
- 最常用的数据结构是树
使用树形结构来描述整个推导过程,比较直观和方便。 - 高效推导技术的实现:递归下降法和 LL(1) 法,都避开了低效率的回溯法。
- 归约法:自底向上
推导的逆过程。- 最常用的数据结构是栈。
- 推导法:自顶向下。
- yacc 可以将语法规则文件转换成对应的 C 代码文件,编译这个 C 代码文件就可得到一个可执行程序
可以进行语法分析。 - yacc 使用流程:
- 词法分析:
- 编写词法规则文件
比如文件名 cparser.l。(2、3、4 只是为了测试 1) - 使用 lex 工具,执行
lex cparser.l,生成 C 代码文件默认文件名 lex.yy.c。 - 使用编译工具
比如 g++,执行g++ lex.yy.c -o lexcparser -ll,生成可执行程序lexcparser。 - 对 C 代码
比如 test.c进行词法分析,执行lexcparser test.c。
- 编写词法规则文件
- 编写语法规则文件
比如文件名 cparser.y。 - 使用 yacc 工具,执行
yacc -d cparser.y,生成两个 C 代码文件默认文件名 y.tab.c 和 y.tab.h。 - 根据 y.tab.h 修改词法规则文件
cparser.l。 - 使用 lex 工具,执行
lex cparser.l,生成 C 代码文件默认文件名 lex.yy.c。 - 使用编译工具
比如 g++,执行g++ y.tab.c lex.yy.c -ll -ly -o cparser,生成可执行程序cparser。 - 对 C 代码
比如 test.c进行词法分析,执行cparser test.c。
- 词法分析:
语义分析在语法分析的时候实施:
- 语法制导转换
也叫语法制导翻译:基本思想就是在文法产生式中设置一些动作,在这些动作里可以开展语义分析或采集信息为后续某个产生式里的动作对应的语义分析做准备。 - 语义分析的分类:
- 静态语义检查:编译过程中针对输入源码的语义检查。
- 动态语义检查:在程序运行过程中的检查
比如检查数组操作是否越界,需要编译器在目标程序中插入额外的检查代码。
生成 IR:
- IR 的逻辑形式:
- 【Java 字节码】单地址:指令的操作数和操作结果都存在栈中。
- Android 平台[1]:对于 ARM 这种寄存器较多的 CPU,如果使用单地址 IR 的话明显是一种浪费。
- 二地址:操作结果存在操作数的存储空间中。
- 三地址:操作数、操作结果都有自己的存储空间。
- 【Java 字节码】单地址:指令的操作数和操作结果都存在栈中。
- 生成 IR 的时机:在语法分析中设置对应的动作。
优化器:
- 优化是在翻译过程中对原程序进行有条件的
安全的,不能改变原程序的语义改进。 - CFG
Control Flow Graph,控制流图:- CFG 利用了数据结构中的图来表达相关信息:
- 基本块:包含一行或多行代码,按从上到下的顺序执行
分支或跳转前后的代码分别放在不同的基本块中。 - 边:表示跳转关系,有方向
对于基本块,入边和出边的个数叫入度和出度。
- 基本块:包含一行或多行代码,按从上到下的顺序执行
- 分析 CFG 时需要用到的数据结构——支配树
DT: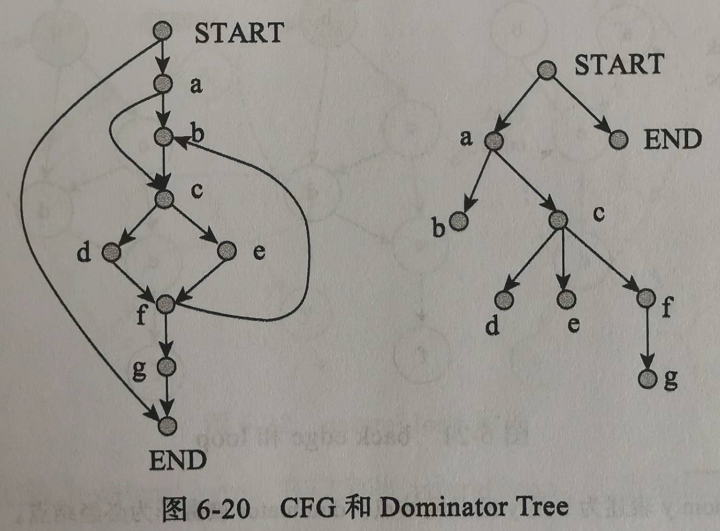
- 结点 x **支配
dom**结点 y:从 START 到 y,怎么走都得经过 x。 - 直接支配结点:离的最近的支配结点。
- 后序支配结点:反向支配
pdom。 - 循环
loop是优化的一个重要目标:- 后向边
back edge:从后继结点指向前驱结点的边。存在后向边就说明存在 loop。- 自然循环
natural loop:外界只能通过入口结点进入该 loop。- reducible loop:CFG 里的 loop 全都是 natural loop。
- 自然循环
- critical edge:一条边的源结点有多个后继结点,且目标结点有多个前驱结点。也是潜在的优化空间。
- 后向边
- 遍历:CFG 采用的是深度优先搜索
DFS中的逆后序遍历PRO,逆后序遍历和后序遍历的过程一样,但是顺序完全相反。
- 结点 x **支配
- CFG 利用了数据结构中的图来表达相关信息:
- 程序的本质是数据和控制,所以优化器对以下信息的分析尤为重要:
- 控制流分析:
- 描述程序结构的相关信息。
- 建立 CFG。
- 循环结构分析。
- 数据流分析
依赖 CFG:- 数据在程序里沿着程序执行路径流动及变化的情况。
- 数据流分析的策略必须保守
保证优化的安全又激进收集尽可能多的信息以提升优化的效果。 - 数据流分析手段:
- 到达定值分析:
- 代码中的某处使用了一个变量,这个变量的值来自于之前何处的定义。
- 定值点:x = 1 中的 x。
- 如果定值点 d 对应的变量在路径上被重新赋值,则称 d 被杀死
KILL。
- 如果定值点 d 对应的变量在路径上被重新赋值,则称 d 被杀死
- 引用点:x = y 中的 x。
- 活跃变量分析:
- 程序中有一个变量 x,变量 x 在后续的代码里会不会被用到。
- 可用表达式分析。
- 到达表达式分析。
- 到达定值分析:
- 控制流分析:
ART 虚拟机的编译模块:
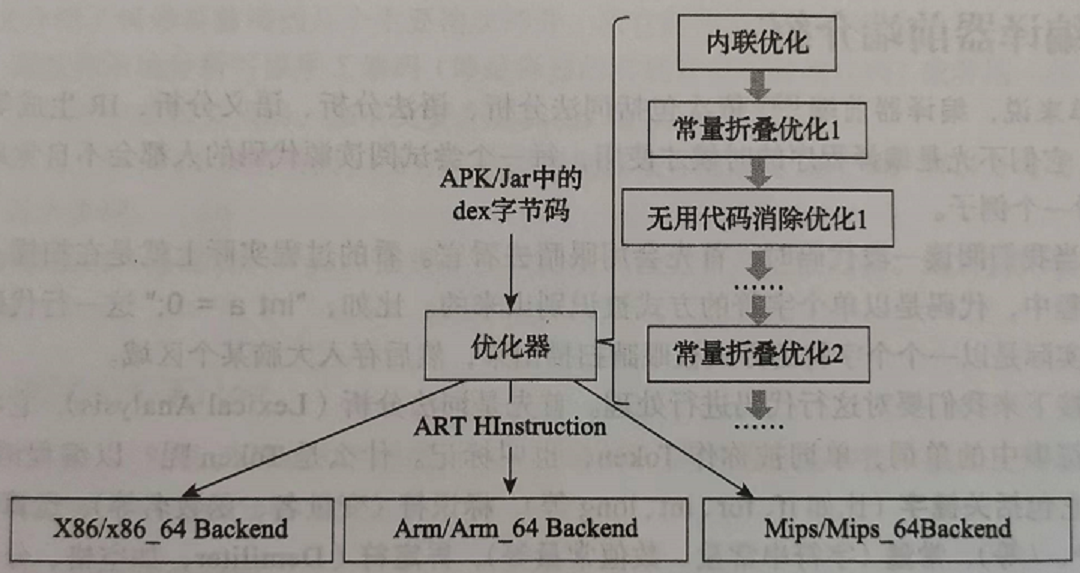
- 没有前端。从 Java 源码到 Dex 字节码的工作是在 APP 开发过程中由 Java 编译器、dex 工具完成的。
- 优化器的输入是 Dex 字节码
优化不是直接针对 Dex 字节码,而是使用了自定义的 IR,输出是 ART 定义的 HInstruction。- 需要一趟一趟地开展,每一趟
Pass的执行都针对一个特定的优化目标。
- 执行顺序有讲究。
- 同一个优化任务可能执行多次。
- 需要一趟一趟地开展,每一趟
- 后端支持 X86、ARM、MIPS 架构的 32 位和 64 位平台。
ART 虚拟机的编译流程:
- 构造 CFG
构造完后,基本块之间的前驱-后继关系就清楚了,但是对优化的价值还比较有限。
入口:block_builder.cc -> HBasicBlockBuilder::Build():- 为 CFG 构造入口和出口基本块。
调用 CreateBranchTarget()对函数的内容进行分析,构造基本块。调用 ConnectBasicBlock()连接基本块就是构造 CFG。
- 分析和处理 CFG。
入口:nodes.cc -> HGraph::BuildDominatorTree():- 创建比特位图数组,用于标记哪些基本块被访问过。
调用 FindBackEdges()深度搜索 CFG 对象,找到 back edge代表 CFG 中存在循环关系,建立基本块之间的关系。调用 RemoveDeadBlocks()移除 Dead 基本块。调用 simplifyCFG()简化 CFG。先确定循环的头和尾结点,再确定循环内包含的所有结点。调用 ComputeDominanceInformation()构造 CFG 的 DT。调用 AnalyzeLoops()分析 CFG 中的循环。
- 将 IR 转换成静态单赋值
SSA形式,并进行数据流分析。- SSA 形式 IR 和原 IR 区别:
SSA 中每个变量只能被赋值一次有利于到达定值分析,每修改一次,变量的下标新变量会 + 1。当不能确定使用的变量的版本时,会使用 PHI 函数构造新变量。 - 入口:instruction_builder.cc -> HInstructionBuilder::Build():
以 PRO逆后序遍历基本块。
调用 InitializeBlockLocals()初始化基本块内的变量,包括添加 PHI 函数。- 遍历基本块里的 dex 指令。
调用 ProcessDexInstruction()将 dex 指令翻译成 ART IR就是 HInstruction。
- 更进一步的处理:ssa_builder.cc -> SsaBuilder::BuildSsa()
- SSA 形式 IR 和原 IR 区别:
- 优化 IR。
入口:optimizing_compiler.cc -> RunOptimizations():- 调用各个优化类的构造方法创建实例。
将几个优化方法装进数组,调用 RunOptimizations()进行第一趟优化。调用 MaybeRunInliner()进行 HInliner 优化。将几个优化方法装进数组,调用 RunOptimizations()进行第二趟优化。调用 RunArchOptimizations()针对特定 CPU 架构进行优化。
- 分配物理寄存器。
- 分配寄存器要解决 IR 里使用的无限个数的虚拟寄存器
无论是 dex 指令码还是 HInstruction,操作的都是虚拟寄存器和只有有限个数的物理寄存器之间的矛盾:当物理寄存器不够用时,优化器需要生成额外的代码,将物理寄存器里的数据先保存到内存从而给别的指令腾出该寄存器,用完之后,再将内存里保存的数据重新加载到物理寄存器中。 - ART 里对物理寄存器的分类:
- 核心寄存器:除浮点寄存器等特殊寄存器之外的寄存器。
- 浮点寄存器:用于浮点计算的寄存器。
- 寄存器对:两个寄存器合起来构成一个能支持更多比特位操作数的寄存器。
- 寄存器分配算法[2]:
- 图着色法:该算法比较耗时
对于支持动态编译的语言影响很大,但是分配效果较好。 - 线性扫描寄存器分配法
LSRA:极大降低算法的复杂度,分配效果在可接受范围内。 - 【ART】基于 SSA 形式 IR 的线性扫描寄存器分配法。
- 图着色法:该算法比较耗时
- 入口:optimizing_compiler.cc -> AllocateRegisters():
调用 liveness.Analyze()线性化 CFG、给 IR 编号、计算 lifetime interval。调用 AllocateRegisters()。调用 GetNumberOfCoreRegisters() 和 GetNumberOfFloatingPointRegisters()分别针对核心代码器和浮点代码器做线性扫描,为代码生成器添加已经分配好物理寄存器的 Location。调用 Resolve。调用 InitializeCodeGeneration()确定函数对应栈帧的大小。
- 分配寄存器要解决 IR 里使用的无限个数的虚拟寄存器
- 将 IR 翻译成机器码。
入口:code_generator.cc -> CodeGenerator::Compile():调用 Initialize()创建标签数组,元素个数和基本块数一致。调用 GenerateFrameEntry()创建栈帧。- 遍历基本块。
调用 HInstruction -> Accept()将 IR 转换成机器码。
调用 Finalize()将生成的机器码拷贝到指定的内存块。
Tips
第 6 章:编译 dex 字节码为机器码
https://weichao.io/f867eb9c1f1d/