第 3 章:深入理解 Dex 文件格式
本文最后更新于:1 年前
Reference
Dex 文件格式:
- Dex 文件是 Android 平台上 Java 源码文件经编译和处理后得到的字节码文件。
- 重复造轮子
不直接使用 Class 文件格式的原因:Android 系统主要针对移动设备内存、存储空间相对 PC 平台而言较小,且主要使用 ARM 的 CPU通用寄存器更多,寄存器的存取速度比位于内存中的操作数栈的存取速度要快得多,Dex 中的指令码也叫操作码可以利用寄存器来存取参数。 - Dex 和 Class 文件格式对比:
- 最终产物不同:
- PC 平台:每一个 Java 源码文件都会对应生成一个同文件名的 Class 文件,生成的所有文件会打包到一个压缩包
Jar 包内。 - Android 平台:每一个 Java 源码文件都会对应生成一个同文件名的 Class 文件,生成的所有文件会合并成一个 classes.dex 文件。
优:- 进一步去除冗余信息
多个 Class 文件之间可能还是有重复字符串等信息。 - 减少 CPU 和存储设备之间 I/O 操作的次数
一个 Class 文件可能依赖另外一个 Class 文件。
- 进一步去除冗余信息
- PC 平台:每一个 Java 源码文件都会对应生成一个同文件名的 Class 文件,生成的所有文件会打包到一个压缩包
- 字节序不同
但是一个字节内的比特顺序都一样:- Class 文件的字节序是 Big Endian。
- Dex 文件默认的字节序是 Little Endian
ARM CPU、X86 CPU 采用的也是 Little Endian,保持一致了。
- Dex 新增的 LEB128
Little Endian Based 128数据类型:- 唯一功能是用于表示 32 位长度的数据。
- 进一步减少空间占用:
- 每个字节的第 7 位数据用于表示这个 LEB128 数据是否结束
所以小值可以就占 1 个字节,大值最多用 5 个字节:1 表示非结尾字节,0 表示结尾字节。 - 每个字节的前 7 位数据按顺序组合为一个 32 位的数据。
- 每个字节的第 7 位数据用于表示这个 LEB128 数据是否结束
- SLEB128:有符号的整数,结尾字节的第 6 位用于表示是否为负数。
- ULEB128:无符号的整数。
- ULEB128p1:无符号的整数,值为 ULEB128 - 1,使得 -1 这个负数只要 1 个字节就可以表示。
- 【相同点】数据类型的字符串描述:
- 原始数据类型:
B、C、D、F、I、J、S、Z,分别表示 Java 类型的byte、char、double、float、int、long、short、boolean。 V表示void,只能用于表示方法的返回值类型。- 引用数据类型:
L类的全路径名; - 数组:
[数据类型
- 原始数据类型:
- Class 的 MethodDescriptor 和 Dex 的 ShortyDescriptor
简短描述,描述方法的参数和返回值信息:- MethodDescriptor:
(参数类型)返回值类型 - ShortyDescriptor:
返回值类型 参数类型- ShortyDescriptor -> ShortyReturnType (参数类型)*
- ShortyReturnType ->
V| shortyFieldType - shortyFieldType ->
B|C|D|F|I|J|S|Z|L
【引入问题】引用数据类型用L表示将无法确定参数或返回值的具体类型。
【解决问题】Dex 提供了其他数据表明具体类型。
- MethodDescriptor:
- 最终产物不同:
Dex 文件格式概貌[1]:
| 类型 | 名称 | 描述 |
|---|---|---|
| header_item | header | Dex 文件头 |
| string_id_item[] | string_ids | 字符串信息 |
| type_id_item[] | type_ids | 类型信息 |
| proto_id_item[] | proto_ids | 方法原型信息 |
| field_id_item[] | field_ids | 成员变量信息变量名、类型等 |
| method_id_item[] | method_ids | 成员方法信息方法名、参数和返回值类型等 |
| class_def_item[] | class_defs | 类信息 |
| call_site_id_item[] | call_site_ids | 调用站点信息 |
| method_handle_item[] | method_handles | 方法句柄信息 |
| ubyte[] | data | 数据通过成员变量 xx_off 指向文件的某个位置 |
| ubyte[] | link_data | 保留 |
header_item:
| 类型 | 名称 | 描述 |
|---|---|---|
| ubyte[8] | magic | 魔数 0x6465780A30333500 |
| uint | checksum | 校验和不包括 magic 和 checksum 自己 |
| ubyte[20] | signature | 签名信息不包括 magic、checksum 和 signature 自己 |
| uint | file_size | 文件的大小 |
| uint = 0x70 | header_size | 文件头的大小 |
| uint | endian_tag | 字节序默认是 0x12345678,Little Endian 格式;如果是 0x78563412,表示 Big Endian 格式 |
| uint | link_size | 链接区段的大小如果此文件未进行静态链接,则该值为 0 |
| uint | link_off | 从文件开头到链接区段的偏移量 |
| uint | map_off | 从文件开头到映射项的偏移量 |
| uint | string_ids_size | 字符串标识符列表中的字符串数量 |
| uint | string_ids_off | 从文件开头到字符串标识符列表的偏移量 |
| uint | type_ids_size | 类型标识符列表中的元素数量 |
| uint | type_ids_off | 从文件开头到类型标识符列表的偏移量 |
| uint | proto_ids_size | 原型标识符列表中的元素数量 |
| uint | proto_ids_off | 从文件开头到原型标识符列表的偏移量 |
| uint | field_ids_size | 字段标识符列表中的元素数量 |
| uint | field_ids_off | 从文件开头到字段标识符列表的偏移量 |
| uint | method_ids_size | 方法标识符列表中的元素数量 |
| uint | method_ids_off | 从文件开头到方法标识符列表的偏移量 |
| uint | class_defs_size | 类定义列表中的元素数量 |
| uint | class_defs_off | 从文件开头到类定义列表的偏移量 |
| uint | data_size | data 区段的大小该数值必须是 sizeof(uint) 的偶数倍 |
| uint | data_off | 从文件开头到 data 区段开头的偏移量 |
code_item:
| 类型 | 名称 | 描述 |
|---|---|---|
| ushort | registers_size | 需要使用的寄存器虚拟寄存器,非物理寄存器数量 |
| ushort | ins_size | 方法的输入参数需要占用的字数以双字节为单位。在 art 优化器中,ins_size 是方法的输入参数的个数,也是输入参数占据虚拟寄存器的个数 |
| ushort | outs_size | 方法内部调用时,输出参数需要占用的字数以双字节为单位 |
| ushort | tries_size | try_item 的数量 |
| uint | debug_info_off | 从文件开头到此代码的调试信息(行号 + 局部变量信息)序列的偏移量如果没有任何信息,该值为 0。该偏移量(如果为非零值)应该是到 data 区段中某个位置的偏移量。数据格式由 debug_info_item 指定 |
| uint | insns_size | 指令码数组的大小Dex 文件格式中指令码的长度还是 1 个字节,但是与第一个参数混在一起构成了一个双字节元素 |
| ushort[insns_size] | insns | 指令码数组。insns 数组中的代码格式由随附文档 Dalvik 字节码指定有一些内部结构倾向于采用四字节对齐方式 |
| ushort(可选)= 0 | padding | 使 tries 实现四字节对齐的两字节填充只有 tries_size 为非零值且 insns_size 是奇数时,此元素才会存在 |
| try_item[tries_size](可选) | tries | try 语句的内容只有 tries_size 为非零值时,此元素才会存在 |
| encoded_catch_handler_list(可选) | handlers | catch 语句的内容只有 tries_size 为非零值时,此元素才会存在 |
其余数据结构查询项和相关结构。
Dex 指令码:
- 解析 Dex 文件中存储方法内容的 insns 数组
位于 code_item 结构体内比 解析 Class 文件中存储方法内容的 code 数组位于 Code 属性中难,因为操作所需的参数如果不跟在指令码后面和 Class 指令码一样,就存储在寄存器中不使用操作数栈,对于存储在寄存器中的参数,指令码需要携带一些信息来表示该指令执行时需要操作哪些寄存器。 - insns
指令码数组的元素两个字节长的数据结构: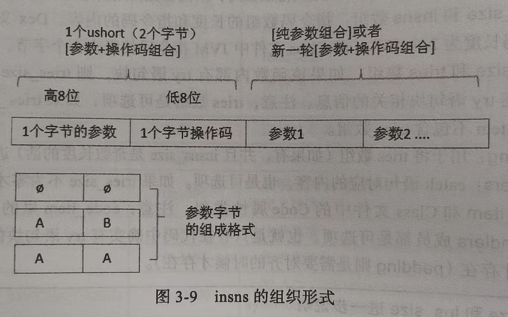
元素有两种结构:- 参数 + 指令码:低 8 位是指令码,高 8 位是参数。
- 纯参数
跟在参数 + 指令码后面。
【参数格式】- 不同字符代表不同的参数。
- 参数的长度由字符个数决定
每个字符占 4 位。 - 一个 Ø 代表 4 位的 0。
- 指令码描述:
- 规则:
- 以 AA|op BBBB 为例:
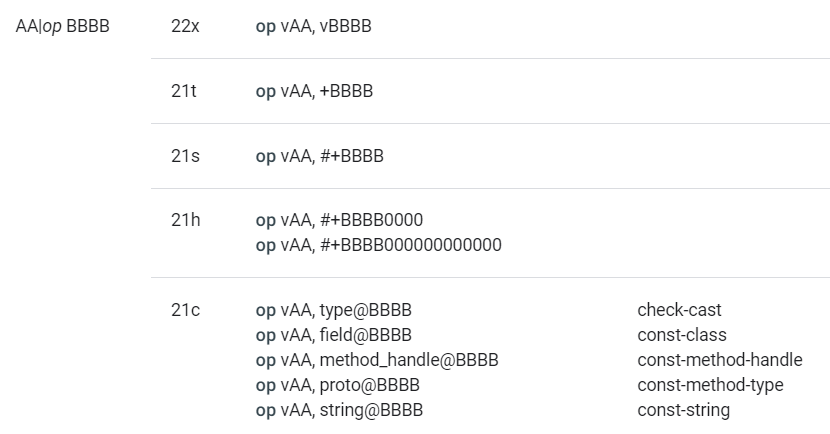
- Format:
- AA|op BBBB:一个 8 位的参数 + 指令码 + 一个 16 位的参数。
- Format ID:
- 22x:需要 insns 数组中的两个元素 + 需要两个寄存器 + 无额外数据。
- 22t:需要 insns 数组中的两个元素 + 需要两个寄存器 + 分支目标。
- 22s:需要 insns 数组中的两个元素 + 需要两个寄存器 + 有符号立即数(短整型)。
- 22h:需要 insns 数组中的两个元素 + 需要两个寄存器 + 有符号立即数 hat(32 位或 64 位值的高阶位,低阶位全为 0)。
- 22c:需要 insns 数组中的两个元素 + 需要两个寄存器 + 常量池索引。
- 语法:
- op vAA, vBBBB:寄存器 A + 寄存器 B
- op vAA, +BBBB:寄存器 A + 相对指令地址偏移量 B
- op vAA, #+BBBB:寄存器 A + 常量值 B
- op vAA, #+BBBB0000:寄存器 A + 常量值 B
- op vAA, #+BBBB000000000000:寄存器 A + 常量值 B
- op vAA, type@BBBB:寄存器 A + 指向 type_ids 数组的索引 B
- op vAA, field@BBBB:寄存器 A + 指向 field_ids 数组的索引 B
- op vAA, method_handle@BBBB:寄存器 A + 指向 method_ids 数组的索引 B
- op vAA, proto@BBBB:寄存器 A + 指向 proto_ids 数组的索引 B
- op vAA, string@BBBB:寄存器 A + 指向 string_ids 数组的索引 B
- Format:
dexdump 工具:
- 解析 dex 文件:把 insns 数组的内容翻译成对应的助记符,并解析其中的参数。
- 使用方法:
- 准备一个 dex 文件
比如 D:\classes3.dex。 - 进入 dexdump 目录
比如 C:\Users\Administrator\AppData\Local\Android\Sdk\build-tools\33.0.2\。 - 打开命令行工具。
- 执行命令:
dexdump.exe -d D:\classes3.dex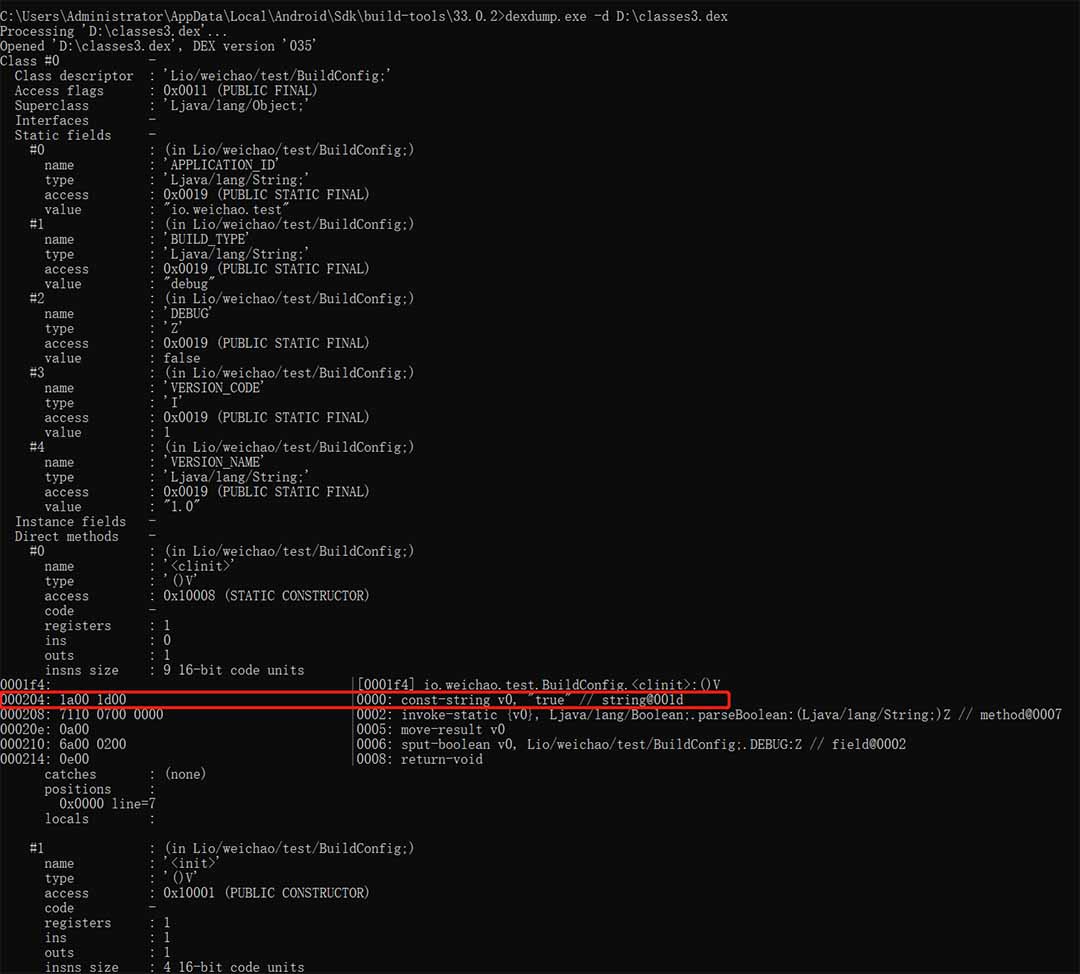
- 准备一个 dex 文件
- 解析红框中的指令码:
- 确定指令码:1a00,先按字节划分为两个元素 1a 和 00,因为 Dex 文件是 Little Endian,所以 【1a 是指令码】
低 8 位,00 是参数高 8 位。 - 确定参数:

经查询,1a 的 Format ID 是 21c需要 insns 数组中的两个元素 + 需要一个寄存器 + 常量池索引,助记符是 const-string vAA, string@BBBB。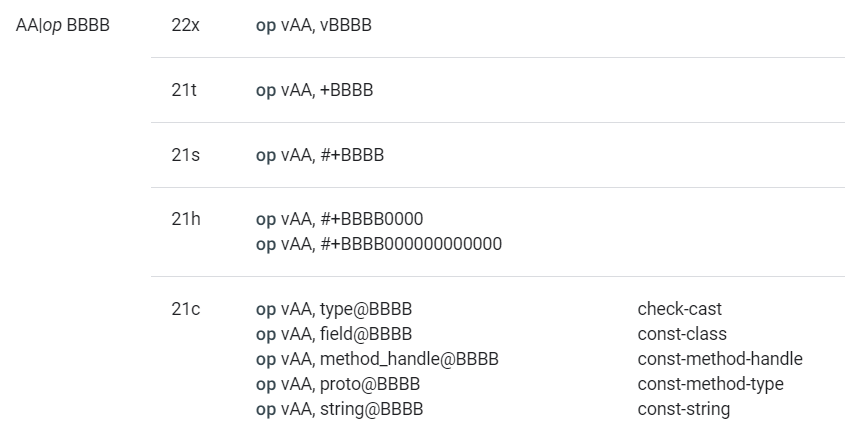
经查询,21c 的 Format 是 AA|op BBBB一个 8 位的参数 + 指令码 + 一个 16 位的参数,语法是 op vAA, string@BBBB寄存器 A + 指向 string_ids 数组的索引 B,对应 1a00 1d00,【寄存器 0 + 指向 string_ids 数组的索引 001d】。
- 确定指令码:1a00,先按字节划分为两个元素 1a 和 00,因为 Dex 文件是 Little Endian,所以 【1a 是指令码】
TODO:自己动手编写一个 Dex 文件格式的解析程序
参考
第 3 章:深入理解 Dex 文件格式
https://weichao.io/eca312d65798/